Introduction: Move the Problem Upstream
For years, reliable element location was treated as a specialist skill. Open DevTools. Inspect the rendered page. Find a unique attribute. Build a CSS selector or relative XPath. Hope tomorrow’s refactor does not break it.
We called this automation engineering, but a surprising amount of it was selector hunting.
AI made the hunt faster. An LLM can generate a locator from an HTML fragment. A browser agent can inspect a page and choose an element at runtime. Both are useful. Neither changes the deeper problem: if the product exposes no stable interface for automation, the test is still reverse-engineering implementation details.
The next architectural step is not a smarter hunter. It is a better contract.
For first-party applications, AI element location in Playwright should become source-first and runtime-verified. Let the agent discover and govern the intended contract in product code, then prove that contract against the running application.
What Is a Capability Contract?
In this context, a capability contract is a stable, intentional interface between product code and automation. It tells a test how a user-facing capability can be addressed without depending on incidental DOM structure.
The contract may be semantic:
page.getByRole("button", { name: "Complete purchase" });Or it may be explicit:
page.getByTestId("checkout-submit");Playwright’s locator guidance recommends user-facing attributes such as roles and accessible names, while also supporting test IDs as explicit testing contracts. The choice depends on what must remain stable. If visible behavior and accessibility semantics define the capability, prefer a role and name. If text is intentionally variable or no suitable semantic handle exists, use a governed test ID.
The distinction matters:
A locator consumes a capability contract. It is not the contract itself.
Generating more locator syntax does not create stability. Product and test code must agree on the interface.
How Selector Hunting Became Automated
The old workflow was manual DOM archaeology. Engineers wrote long CSS or XPath chains tied to markup structure. Playwright explicitly warns that these selectors often break when the DOM changes.
The first AI improvement accelerated the same workflow. We pasted HTML into an LLM and asked for a robust selector. Syntax became cheap, but architecture did not improve. As I argued in Code is Cheap, Context is King, faster generation cannot compensate for missing product context.
Runtime browser agents improved the process again. Playwright MCP operates on structured accessibility snapshots and does not need screenshots or vision models by default. That gives the model meaningful roles, names, and states, making runtime interaction more reliable than pixel guessing.
But it is still an observe-reason-act loop. The agent observes the page, chooses an action, receives the next state, and reasons again. This is valuable for exploration, third-party surfaces, and environments where the repository is unavailable. It is not proof that every locator problem should be solved from the browser.
We automated selector hunting. Now we can reduce the need for hunting.
Source-First, Runtime-Verified
When we own the application, the repository contains information the rendered page cannot explain: component intent, design-system conventions, prop composition, feature flags, and existing testability policies.
An agent asked to automate checkout can inspect the relevant route and components before opening a browser. It can identify an existing role, accessible name, or test ID. If the contract is missing, it can propose the smallest product change: add a meaningful accessible name, expose an approved test ID, or forward the attribute through a design-system component.
That is a better failure mode than inventing this:
page.locator("#checkout > div:nth-child(3) > button");Source analysis also has limits. A test ID may be composed dynamically. A wrapper may forward it through several components. Conditional rendering may hide the element in the tested state. Build tooling may remove test attributes. The source expresses intent; it does not prove runtime availability.
So the architecture needs both surfaces:
- Discover and govern in source. Find the intended interface or propose one.
- Verify at runtime. Confirm that the built application exposes the contract in the correct state.
The discovery step may use probabilistic AI reasoning. The final Playwright locator and assertion remain deterministic. That boundary is the point.
The Governed Workflow
The mature workflow is short:
intent → repository analysis → contract check → change proposal → deterministic CI → runtime verification
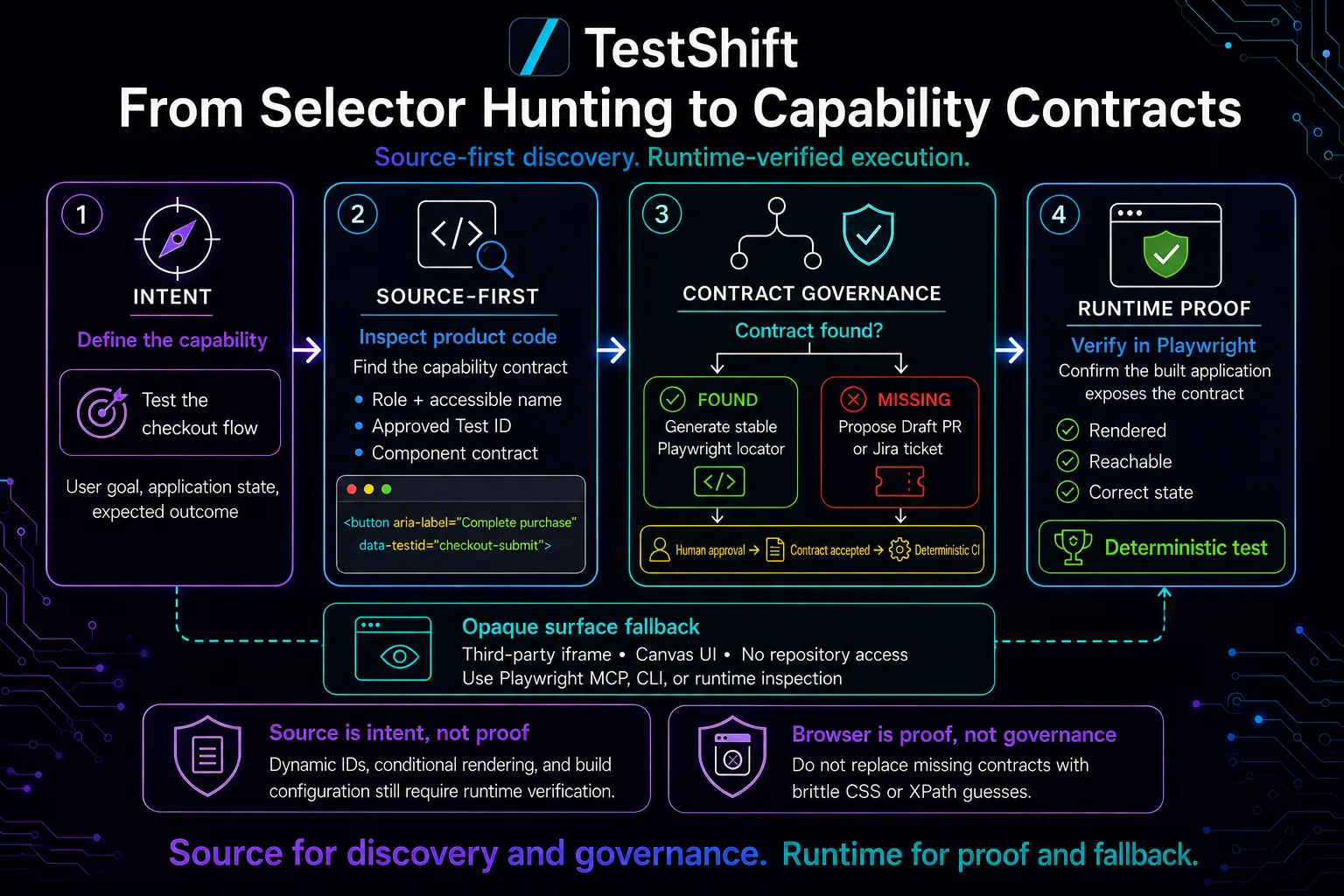
If the contract exists, the agent generates the test and validates it. If it does not, the agent proposes a Jira ticket or Draft PR. It should not silently inject attributes, weaken assertions, or merge its own hypothesis. Product ownership, CI, and code review remain the Quality Gate.
Different surfaces still require different control paths:
| Application surface | Recommended approach |
|---|---|
| First-party UI with repository access | Source-first discovery, then runtime verification |
| Shared design-system component | Trace the component contract, then verify the consuming application |
| Remote microfrontend owned by another team | Verify at runtime and route contract changes to the owner |
| Third-party iframe or payment widget | Runtime-first; the external product owns the source contract |
| Canvas or visually rendered interface | Runtime or vision-based interaction with domain-specific assertions |
| Staging URL without repository access | Runtime discovery using semantic Playwright locators |
Token economics follow from the control flow. A repository lookup is bounded by the relevant files and dependency graph. A runtime agent loop is iterative: every meaningful state change may require another observation and another reasoning step.
The official Playwright CLI makes that runtime path more token-efficient by avoiding forcing page data into model context. That optimizes the loop; it does not remove it. There is no universal savings percentage. The architectural advantage comes from choosing the cheapest reliable surface for each task and constraining what the model must repeatedly observe.
Conclusion: From Hunter to Contract Architect
Selector hunting is not disappearing. Sometimes the browser is the only surface available, and runtime inspection is exactly the right tool.
But for product code we own, browser-only discovery should no longer be the default. The better pattern is to establish stable capability contracts upstream, govern changes through normal engineering controls, and verify the result against the running system.
This changes the role of QA. We stop treating locators as private test implementation details and start treating testability as a shared product capability.
The AI agent does not become an XPath wizard. It becomes an architectural assistant: reading intent, finding contract gaps, and proposing improvements inside governed boundaries.
Stop asking only, “How can the test find this element?”
Start asking, “What contract should the product expose?”
That is the move from selector hunter to contract architect.
Nir Tal is the Founder and Chief Architect of TestShift, dedicated to building AI-native automation architectures and Quality Gates that scale.